商机详情 -
哪个阅读行为感知联系人
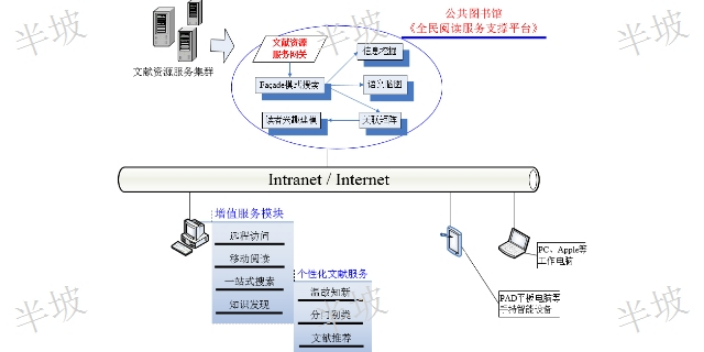
网络资源导读服务工作者要向读者介绍数字化资源的分布情况、检索方式和利用策略,培养读者信息检索能力,包括网络检索、数据库检索、超文本信息检索、全文检索以及光盘检索等。为了提高读者的信息技能,向读者展开有效利用数字资源的培训工作。网络资源导读服务工作富有创造性,是一个综合性的教育过程。不仅传授给读者信息检索知识,更注重培养读者利用信息的能力以及信息理论、方法和技能。此外,为了进一步增强目录学对网络资源的导读作用,开展针对性和目标性更强的RSS(ReallySimpleSyndication)定制服务以满足读者的个性化需求。读者可以通过关键词、图片或其他方式搜索相关内容,从而增加了阅读内容的可选择性和自主性。哪个阅读行为感知联系人
信息抽取是指从多源异构的数据源中提取出实体、属性以及实体之间的关系,在此基础上形成本体化的知识表达,它是知识图谱构建技术的关键[1]。早期信息抽取主要是基于预定规则的抽取技术,工作量庞大且*适用于特定的专业领域,后来人们开始尝试使用统计机器学习的方法,通过标注部分数据得到训练集,在此基础上再使用均方根误差算法(rootmeansquarederror,RMSE)或多项式回归算法(polyno⁃mialregression,PR)等有监督学习算法识别命名实体。创新阅读行为感知数据分析阅读行为感知可以为文学批评和文本分析提供新的视角和方法。
数字阅读指的是阅读的数字化,其主要具有两方面含义:一是阅读对象,即内容以数字方式表现,如网络小说、网页等。二是针对阅读方式而言,区别于实体的纸张,其阅读载体为手机、平板、电脑等。相比于传统的纸质读物,数字化读物具有存储量大、检索便捷、便于保存、成本低廉、易于互动、智能(超文本阅读)等优点,它们可以随时随地被用于无障碍的阅读行为;同时,声音的融入使数字化读物比**只有“图文”的纸质媒体更***、具体、生动。拥有诸多优势的数字化阅读已经对纸质阅读形成了巨大的冲击。统计资料表明,当代大学生普遍利用手机、平板、电脑、阅读器等终端进行消遣娱乐与阅读,其中,阅读内容依次以新闻时事、生活休闲、网络小说、报纸杂志为主。大学生们数字阅读行为非常***且深入,他们将整段或碎片化的时间大量投入到数字阅读中,且偏向于阅读娱乐性、快餐性内容。对于大学生来说,数字阅读是大学生活里不能缺少的一部分,充分掌握数字资源的获取途径与利用方法具有积极的意义。
构建知识图谱有自顶向下和自底向上两种方式。前者通常是指基于百科类网站等高质量的结构化数据源,从中提取本体和模式信息后再加入到知识库中,因而适用于那些内容明确、关系清晰的领域知识图谱构建;而后者是指通过借助特定的技术手段从公开采集的数据中提取模式信息,选择其中置信度较高的新模式,经人工审核后再加入到知识库中[2]。目前大部分知识图谱的构建都采用自底向上的方式,其层次架构按照知识获取的过程可分为信息抽取、知识融合和知识加工。 阅读行为感知,是知识内化的关键步骤。
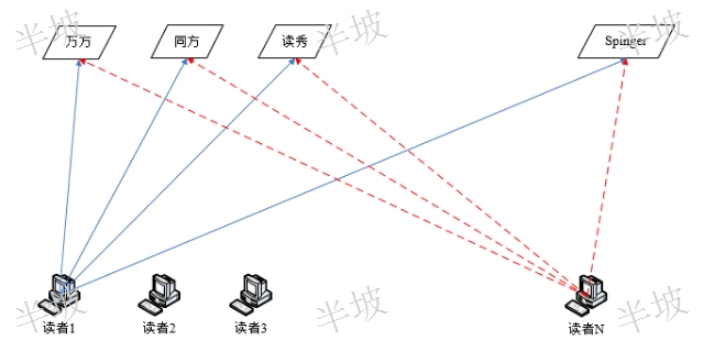
远程访问系统是一种解决使用者由于受到IP的限制而无法访问内部资源的解决方案。通常使用者在外网发送请求到服务器,服务器接收到请求后再发送给使用者,这个过程一般会受到网络带宽、客户端和服务器的性能和系统的负载等情况的直接影响,可能因多人同时访问而无法打开连接,或者因访问电子资源速度过慢而导致超时。目前,图书馆远程访问系统的实现技术主要有三种:代理服务器技术、VPN技术和URL重定向技术。代理服务器技术对网络传输和数据安全要求很高,不能完全满足师生访问电子资源的需求。VPN技术主要面向企业用户,不针对图书馆的远程访问技术,所以无法完成图书馆的数据分析和统计等需求。URL重定向技术设计的远程访问系统弥补了前两者的不足,成为目前远程访问系统实现的***方式。URL重定向技术又称为URL转发技术,是一种可以让多个URL地址在一个网页上可用的万维网技术,当用户打开一个已经被重定向的网址时,这个网页就会用另外一个不同的地址展现。精细阅读感知,让理解更加深入透彻。江苏互联网阅读行为感知
阅读行为感知可以帮助我们理解读者对于不同类型阅读材料的偏好和需求。哪个阅读行为感知联系人
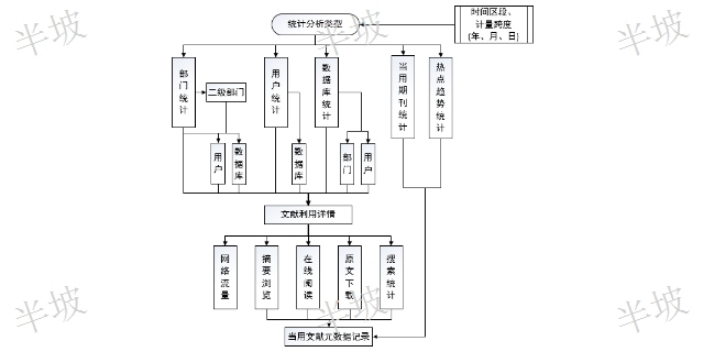
关键词统计作为一种重要的文献统计分析方法,可以帮助我们快速了解到,有关个人信息国内外学者都进行了哪些方面的研究。因此,本文借助文献分析软件Citespace对所搜集文献的关键词进行词频统计,将文献中使用频次排在**的关键词提取出来,。通过对比分析国内外文献的高频关键词,我们可以发现:隐私关注、隐私悖论、个人信息披露行为均受到了国内外学者的关注,但国内外学者对于个人信息研究的侧重点有所不同,国外学者更加注重信息披露行为的模型研究。哪个阅读行为感知联系人