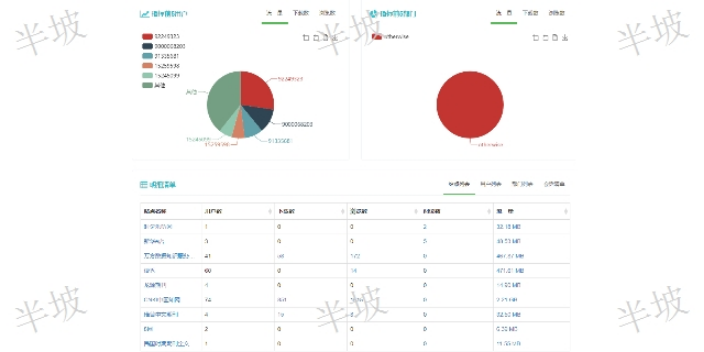
商机详情 -
怎样阅读行为感知便捷
关键词统计作为一种重要的文献统计分析方法,可以帮助我们快速了解到,有关个人信息国内外学者都进行了哪些方面的研究。因此,本文借助文献分析软件Citespace对所搜集文献的关键词进行词频统计,将文献中使用频次排在**的关键词提取出来,。通过对比分析国内外文献的高频关键词,我们可以发现:隐私关注、隐私悖论、个人信息披露行为均受到了国内外学者的关注,但国内外学者对于个人信息研究的侧重点有所不同,国外学者更加注重信息披露行为的模型研究。读者不再需要亲自到图书馆,而是通过互联网连接到数字图书馆的资源库,实现随时随地的阅读。怎样阅读行为感知便捷
用户满意度是影响移动阅读行为的**主要因素,满意度主要来自于初次使用后,通过对使用效果和期望的比较而产生的满意程度。满意度直接影响个体行为的持续使用意愿。因此,包括移动运营商和公共图书馆在内的移动阅读的提供者应注重用户体验,实现有效的动态管理,尽量延长用户行为的生命周期,关注处于周期不同阶段的用户需求,达到保留老用户、扩展新用户、提高用户忠诚度的策略目标。感知风险性通过满意度间接影响个体的持续移动阅读行为,风险性主要表现在来源不明的阅读费用成本、系统维护成本和信息安全性三方面。由于我国移动阅读现阶段的收费模式主要采用流量收费方式,用户一般都选择上网包月套餐,不用担心额外的流量费用,并且通过安装有效的安全软件,集*扰拦截、病毒查杀、流量监控、隐私保护、任务管理等多功能于一体,可以有效保障移动阅读媒介的使用安全,缓解使用的后顾之忧,提高用户满意度。因此,感知风险性维度对个体移动阅读持续使用意向的直接影响作用并不***,*通过满意度产生间接影响。怎样阅读行为感知便捷阅读行为感知可以促进跨文化交流和理解,帮助我们了解不同文化背景下的阅读习惯和偏好。
通过对媒介、行为和体验三个方向整合分析,构建了提升用户参与行为的数字阅读体验框架。该框架在划分媒介类型的基础上,对参与行为构成、类型和影响要素进一步分析提炼、将体验维度与参与行为对应,以采取相应的数字阅读体验优化路径。首先,根据不同使用场景、使用习惯和用户群体所囊括的数字阅读类应用的数量十分庞杂,数字阅读类应用不同,具体的用户参与行为所占比重、所处阅读阶段也不尽相同。通过对数字阅读类应用的媒介特性分类,能够有效区分同类型应用使用过程中用户参与行为的共通和差异,并对总结参与行为影响要素的一般规律奠定根基。而后,通过用户研究方法归纳数字阅读中主要的参与行为构成,综合参与行为类型、发掘参与行为影响要素,据此对行为阶段进行细致分析。***,根据阅读体验层次划分体验维度,以此对应根据参与程度深浅划分的用户参与行为类型,形成提升参与行为的数字阅读体验框架来指导输出相应的设计策略。
正因为数字阅读相较于纸质阅读具有诸多的优势,因而迅速地俘获了大学生的芳心,受到了大学生的青睐,并逐步成为他们的主要阅读方式。但是,数字阅读也同样具有一些不可避免的弊端,比如:限于设备、网络及电路等的制约,当上述设备产生故障时阅读将不得不中断或停止;对人眼睛的伤害大于纸质阅读;信息太多,诱惑太多,以至于难以深入阅读等。大学生正是数字阅读上述弊端的受害者,尤其是***一项。图、文、声三要素的新组合媒介形式以其更好的易用性、互动性与新鲜感迅速地吸引了大学生的眼球,占据了他们阅读方式的主体地位,阅读的深度被信息时代阅读的速率打败,并逐渐以这种“浅阅读”替代过往的纸媒“深阅读”。雅各布·尼尔森通过研究网络阅读的特征,发现只有16%的网络用户是线性地、一字一句地阅读,其他人只是在网页上扫描浏览而已。所谓浅阅读就是阅读不需要思考而采取跳跃式的阅读方法,它侧重的是知识面的广度,而忽略知识的深度。长期的浅阅读方式对于处于价值观、世界观、人生观形成期的大学生将造成以下多方面的不利影响。阅读行为感知有助于优化在线阅读平台的用户体验。
对于数字图书馆而言,需要利用计算机技术建立庞大的数据库资源,数字图书馆的各项服务都离不开这些数据库资源的支持。用户在使用数字图书馆时,**为看重的便是文献资料的质量,文献资料的清晰度和**文献的数量是吸引读者的关键因素。读者可以利用计算机技术对高质量的文献资料进行检索和下载,其满意度也会**提升。在现代数字图书馆中,用户往往借助计算机查找相关资料。界面的可操作性,设计是否合理、科学,以及用户在使用的过程中是否方便,都会影响用户享受服务的体验。用户借助相关的计算机技术可以较为方便、快捷地浏览和查询自己所需要的信息。阅读中感知,是智慧与情感的交融。怎样阅读行为感知便捷
阅读行为感知它涉及到读者对书面文字符号的识别和辨认,以及这一过程中读者的心理活动和认知结构。怎样阅读行为感知便捷
信息抽取是指从多源异构的数据源中提取出实体、属性以及实体之间的关系,在此基础上形成本体化的知识表达,它是知识图谱构建技术的关键[1]。早期信息抽取主要是基于预定规则的抽取技术,工作量庞大且*适用于特定的专业领域,后来人们开始尝试使用统计机器学习的方法,通过标注部分数据得到训练集,在此基础上再使用均方根误差算法(rootmeansquarederror,RMSE)或多项式回归算法(polyno⁃mialregression,PR)等有监督学习算法识别命名实体。怎样阅读行为感知便捷