商机详情 -
河南网络智慧导读
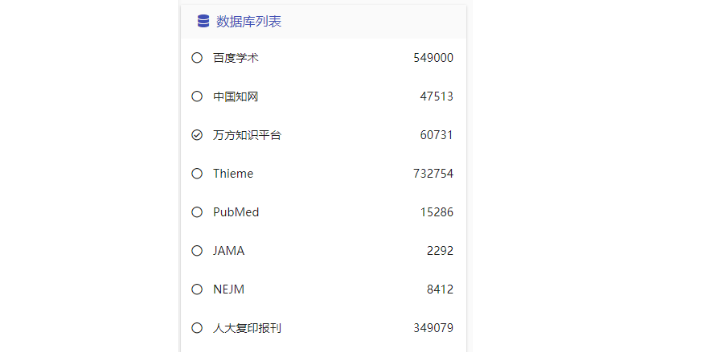
个性化阅读推荐系统的设计始于高效且精确的数据采集、处理与分析。在智慧图书馆中,用户每天进行搜索、阅读和下载等互动行为均会产生大量数据。以大型智慧图书馆为例,其每月会新增数千份电子书和期刊,且数百万用户的日常活动会生成海量数据记录,包括搜索查询、点击和下载等行为数据。这些数据是设计个性化阅读推荐系统的基础,需要收集和处理,以便后续进行分析和应用。数据采集必须***覆盖用户数据,包括用户的注册信息、借阅记录、阅读习惯,以及用户与智慧图书馆资源的交互方式等。依托上述数据,个性化阅读推荐系统可掌握用户的基本兴趣和偏好,鉴别用户潜在的兴趣领域和行为模式,从而为推荐给予数据方面的支持。为读者提供更加个性化的阅读推荐,帮助读者发现感兴趣的内容、拓宽阅读视野、提高阅读效果。河南网络智慧导读
目前智慧阅读服务的研究成果主要集中在服务系统、服务内容、用户需求与行为等方面。面对新一代人工智能技术的不断迭代,阅读服务面临前所未有的机遇与挑战,当前学术阅读智慧化服务存在哪些问题?如何依托AIGC技术赋能实现服务优化?这些问题亟需得到探究与明晰,但目前学界尚缺少聚焦学术阅读智慧化服务领域的跟踪研究。因此,本文拟利用内容分析法剖析目前国内外典型学术平台的智慧阅读服务现状,总结存在问题,并探索AIGC技术赋能改进图书馆学术阅读智慧化服务的路径。四川数字图书馆智慧导读文本语义脑图检索系统通常会针对某一文献内容特征进行单一维度的文献聚类细分。

智慧导读调用原生数据后依次通过模态识别、特征提取、融合计算三阶段的数据融合,实现多模态原生数据向聚焦特定服务目标的融合数据转化,经实体、事件、关系三种维度的信息抽取,实现融合数据向结构化综合信息有序转化,进而存储各类中间数据于相应数据库;调用中间数据后依次通过目标设定、方法模型及工具综合应用、结果评估三阶段的数据分析,实现数据价值深度挖掘以获取直接作用于图书馆数智服务的多维主题标签及深度数据,经知识融合、知识评估、知识推理三阶段的知识发现,实现多维主题标签及深度数据向满足任务智能决策需要的通用知识及领域知识转化,进而存储各类智慧数据于相应数据库。
智慧导读依赖于大数据和机器学习技术,它通过对用户阅读行为、兴趣偏好、历史记录等数据进行深度分析和挖掘,为用户推荐个性化的阅读内容。这种方式实现了对用户数据的自动化处理和高效利用。而传统的书籍推荐方式往往基于编辑或销售人员的经验判断、**或**榜单等,这种方式虽然有其合理性,但可能缺乏足够的个性化和精细性。智慧导读通过机器学习和算法优化,能够持续学习和适应用户的阅读行为变化,从而提供越来越精细的推荐。而传统的推荐方式可能因为主观因素或信息更新的滞后,其推荐精细度可能受到限制。推荐范围和实时性:智慧导读可以涵盖海量的书籍资源,并根据实时数据更新推荐内容,使得用户能够接触到更多元、更及时的阅读选择。传统的推荐方式则可能受限于推荐源的数量和更新速度,无法提供如此***和及时的推荐。《智慧导读》是上海半坡网络技术有限公司研制开发的一种主动介入的实时文献内容知识发现服务产品。
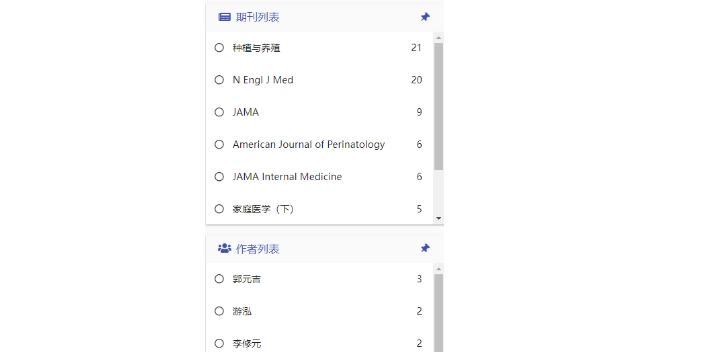
智慧图书馆可根据现实需求选择恰当的推荐算法,且按照用户反馈开展算法优化,保障推荐的精细行业交流1552025年3月度与多样性。用户反馈与系统迭代是个性化阅读推荐系统持续改进的关键。个性化阅读推荐系统必须不断收集用户对推荐结果的反馈,对点击率、借阅率、阅读时长等相关数据进行分析,即刻调整推荐策略。同时,采用机器学习技术,个性化阅读推荐系统可不断修正推荐模型,逐步提高推荐的精细度与个性化水平。通过上述流程,智慧图书馆可设计出更加***的个性化阅读推荐系统,给予用户更加个性化的阅读推荐服务,帮助用户更高效地获取感兴趣的书籍及资源,进而提高用户体验以及智慧图书馆的服务水平[5]。智慧阅读服务系统与平台方面的研究主要包括 出版与阅读服务系统、图书馆阅读服务系统等。江西智慧导读标志
信息社会发展下,教育领域的传统学习方式 和图书馆服务模式。面临挑战与机遇。河南网络智慧导读
首先,智慧导读系统会收集用户在阅读过程中的各种数据,包括但不限于用户的阅读时长、阅读偏好、阅读历史、点击行为、评论反馈等。这些数据可以通过用户在平台上的行为自动记录,也可以通过用户主动填写问卷或设置偏好等方式获取。收集到的原始数据可能包含噪声、重复或无效信息,因此需要进行数据清洗和预处理。这一步包括去除重复数据、填充缺失值、转换数据格式等操作,以便进行后续的数据挖掘工作。利用机器学习和数据分析技术,对用户数据进行深度挖掘。这包括对用户的阅读习惯、兴趣偏好、情感倾向等进行分析,发现用户潜在的阅读需求和兴趣点。同时,通过对用户数据的聚类、分类和关联规则挖掘等,可以发现用户群体之间的相似性和差异性,为后续的推荐算法提供依据。河南网络智慧导读