商机详情 -
广东一站式阅读行为感知
语义网络作为人工智能的重要应用领域之一,可以给用户提供一个更加准确、更加智能的知识获取环境。而知识图谱是实现语义网络的技术基础,是通向语义网络环境的鲜明道路[1]。在智慧学习的大环境下,叠加近年来****的防控需求,在线阅读已越来越多地成为广大读者的优先阅读方式。如果能够有效获取读者的阅读行为并构建对应的知识图谱,对于图书馆而言,可以及时了解其在阅读过程中的实际需求,继而进行针对性的阅读指导并为读者推荐个性化的阅读内容;对于出版商而言,可以及时调整、改进电子出版物的内容编排及后续再版工作,以更好地适应目标读者群体的实际需求。因而,此项研究工作对于进一步提升读者的阅读学习效果,完善图书馆的智慧化阅读服务,推动促进全社会形成良好的智慧学习环境大有裨益。数字图书馆的阅读行为感知还涉及到读者的个性化需求和行为习惯。广东一站式阅读行为感知
随着计算机技术发展,人类迎来“全媒体”时代。全媒体指不同的媒介与运营机构通过各种媒体形式,向用户提供多种不同终端的多元信息接收方式,用户在信息接收上不再有时间、空间与方式的隔阂与障碍[1]。阅读行为亦受到全媒体影响,以纸质载体为**的传统阅读渠道不再是读者的***选择,阅读过程中的各阅读阶段涌现了许多选择项。图书馆的阅读服务需要跟进阅读行为多渠道选择的潮流,从阅读引导、阅读提供和阅读互动等方面顺应用户阅读行为的发展,因势利导提升内容服务[2]。因而,了解读者为何会选择多种渠道进行阅读、影响读者选择多种渠道的因素、这些影响因素之间有怎样的相互影响,显得尤为重要。本研究以技术采纳模型为基础,结合阅读动机理论,探讨全媒体时代用户选择多渠道阅读的原因,构建阅读的多渠道选择模型,并对模型进行验证。天津怎样阅读行为感知透过感知阅读,发现文字背后的秘密。
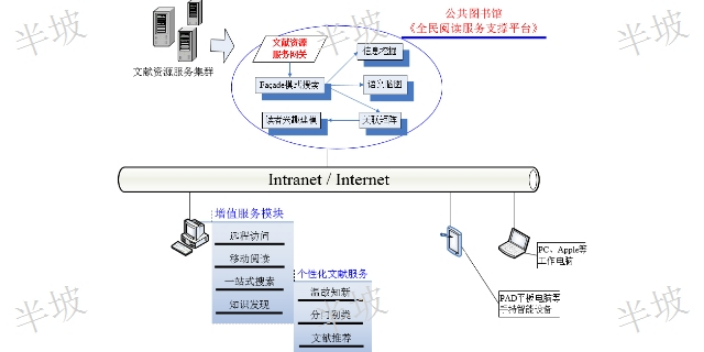
构建知识图谱有自顶向下和自底向上两种方式。前者通常是指基于百科类网站等高质量的结构化数据源,从中提取本体和模式信息后再加入到知识库中,因而适用于那些内容明确、关系清晰的领域知识图谱构建;而后者是指通过借助特定的技术手段从公开采集的数据中提取模式信息,选择其中置信度较高的新模式,经人工审核后再加入到知识库中[2]。目前大部分知识图谱的构建都采用自底向上的方式,其层次架构按照知识获取的过程可分为信息抽取、知识融合和知识加工。
信息抽取是指从多源异构的数据源中提取出实体、属性以及实体之间的关系,在此基础上形成本体化的知识表达,它是知识图谱构建技术的关键[1]。早期信息抽取主要是基于预定规则的抽取技术,工作量庞大且*适用于特定的专业领域,后来人们开始尝试使用统计机器学习的方法,通过标注部分数据得到训练集,在此基础上再使用均方根误差算法(rootmeansquarederror,RMSE)或多项式回归算法(polyno⁃mialregression,PR)等有监督学习算法识别命名实体。感知阅读节奏,体验文字的音乐之美。
按照媒介延伸的主要感官类别可以把媒介分成视觉空间型和声觉空间型媒介,在感官类型维度划分基础上加入数字阅读类应用的内容特性这一维度,能够概括现有的数字阅读媒介类型。姜洪伟提出根据数字阅读内容主要特征划分为信息性读物和知识性读物,谢新洲、石林在《数字阅读构筑内容生态内核》一文对胡晓东的访谈中其将数字阅读行业划分为资讯、故事、知识三个分支。本文为了让数字阅读内容特性划分普适性更强,分为即时实用性刺激性内容和经典抽象性逻辑性内容,得到数字阅读类应用的媒介基本类型,根据感官类型和内容特性两个维度划分数字阅读类应用可以分成四个典型类型,按照该分类标准划分数字阅读类应用基本可以囊括现有市场相关产品,较为完整且凸显产品特点。具体数字阅读类应用的典型类型中其用户参与行为的表现有所侧重,那么以参与行为为导向进行设计来优化具体应用某一环节的阅读体验更具实践价值。读者不再需要亲自到图书馆,而是通过互联网连接到数字图书馆的资源库,实现随时随地的阅读。哪个阅读行为感知选择
阅读行为感知可以帮助我们评估不同媒介对于读者注意力和认知的影响。广东一站式阅读行为感知
提高读者的信息素质,包括信息意识、信息能力和信息道德等。读者的信息需求可分为普通“大众型”的消遣阅读需求和专业“学术型”的阅读需求两个层次。网络资源导读服务工作者要开展信息源查询、网址查询、操作咨询、信息内容等服务工作,还要开展定题服务、引文检索、项目查新等各种资源服务工作。针对不同的读者进行不同的信息检索教育,让读者通过运用各种检索工具和检索手段来获取信息,再根据自身需要对这些信息进行选择,将信息有效的加工、组织起来,进而消化并吸收,创造新的知识。广东一站式阅读行为感知