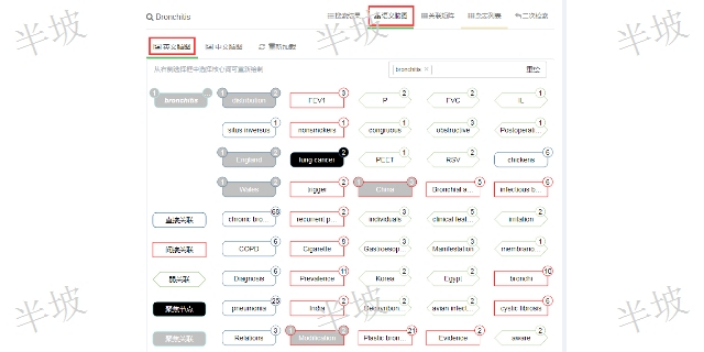
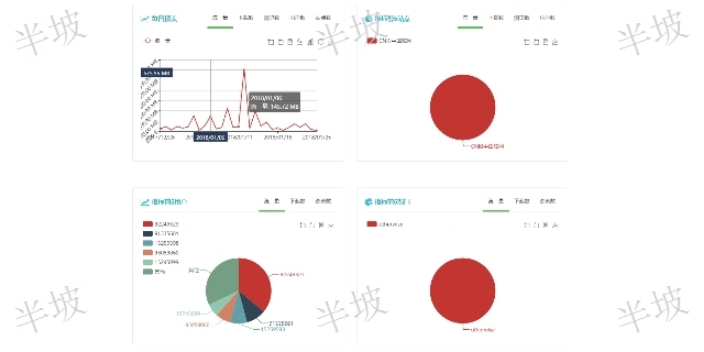
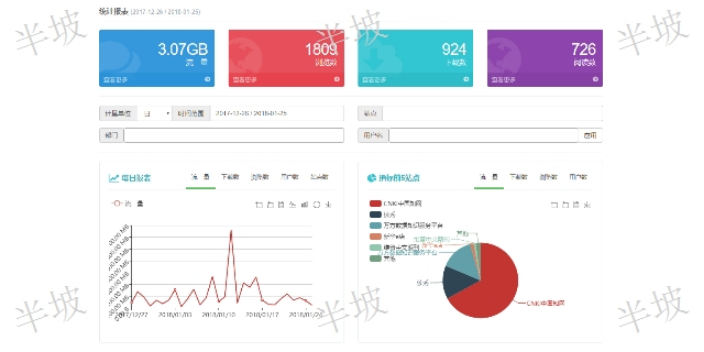
商机详情 -
江西信息阅读行为感知
数据挖掘是依靠先进的信息技术从海量的数据信息中快速、准确地提取所蕴藏的信息,并将这些信息用于工作实践中。在数字图书馆中,数据挖掘具有特定的流程和层次,在数字图书馆信息参考查询中应用数据挖掘技术,具有很多优势。***,利用数据挖掘技术能够提高查询的效率,从而能够缩短等待的时间。第二,利用数据挖掘技术能够实时获取读者在互联网上的阅读行为和阅读偏好,可以依据这些信息分析出用户的具体需要。第三,在文献资源的检索过程中,应用数据挖掘技术能够有效提升文献检索的效率。相较于传统的图书馆而言,数字图书馆对文献量的需求更大,必须制订科学合理的采购计划,才能实现馆藏数字资源的均衡化。在数字图书馆中,对于一些用户较少的文献资料可以少量采购,而对于一些用户需求量大的文献资料可以大量采购。利用计算机挖掘技术,可以有效地分析出不同文献的利用效率,以便科学准确地预测出图书馆馆藏文献的变化趋势、采购趋势以及数量要求,从而为采购提供决策依据。读者可以通过关键词、图片或其他方式搜索相关内容,从而增加了阅读内容的可选择性和自主性。江西信息阅读行为感知
对于数字图书馆而言,需要利用计算机技术建立庞大的数据库资源,数字图书馆的各项服务都离不开这些数据库资源的支持。用户在使用数字图书馆时,**为看重的便是文献资料的质量,文献资料的清晰度和**文献的数量是吸引读者的关键因素。读者可以利用计算机技术对高质量的文献资料进行检索和下载,其满意度也会**提升。在现代数字图书馆中,用户往往借助计算机查找相关资料。界面的可操作性,设计是否合理、科学,以及用户在使用的过程中是否方便,都会影响用户享受服务的体验。用户借助相关的计算机技术可以较为方便、快捷地浏览和查询自己所需要的信息。创新阅读行为感知排行榜阅读行为感知可以帮助我们理解读者对于不同类型阅读材料的偏好和需求。
要进行数字图书馆资源建设,首先要扩展学术资源范围,数字资源作为数字图书馆的重要资源,是提高服务质量的根本保障,因此数字图书馆在建设过程中要充分挖掘互联网资源,重视资源的整合与加工。虽然我国的图书馆一直很重视资源建设,但其大多是文献型资源,导致资源建设受到阻碍。大数据时代,数字图书馆的建设需要开拓思维,拓展数据库资源,同时要注重对用户信息的采集,包括用户使用数字图书馆的行为信息,以便于有针对性地提供用户所需要的资源与服务。大数据具有复杂性与多样性的特点,单纯的文献资源无法满足用户的需要,因此必须注重增加数字图书馆资源整合的广度,将各类信息进行整合,将数字图书馆资源与社会资源进行合理整合。除此之外,在大数据环境下,数字图书馆应该具备帮助用户解决复杂问题的功能,从各个方面尽力满足用户的需求。加强数字图书馆资源组织加工深度,重视对用户行为信息资源的深度挖掘,使其变成知识服务的高效资源。
远程访问系统是一种解决使用者由于受到IP的限制而无法访问内部资源的解决方案。通常使用者在外网发送请求到服务器,服务器接收到请求后再发送给使用者,这个过程一般会受到网络带宽、客户端和服务器的性能和系统的负载等情况的直接影响,可能因多人同时访问而无法打开连接,或者因访问电子资源速度过慢而导致超时。目前,图书馆远程访问系统的实现技术主要有三种:代理服务器技术、VPN技术和URL重定向技术。代理服务器技术对网络传输和数据安全要求很高,不能完全满足师生访问电子资源的需求。VPN技术主要面向企业用户,不针对图书馆的远程访问技术,所以无法完成图书馆的数据分析和统计等需求。URL重定向技术设计的远程访问系统弥补了前两者的不足,成为目前远程访问系统实现的***方式。URL重定向技术又称为URL转发技术,是一种可以让多个URL地址在一个网页上可用的万维网技术,当用户打开一个已经被重定向的网址时,这个网页就会用另外一个不同的地址展现。阅读行为感知,开启对世界的全新认知。
研究表明,***,在使用阅读类应用的过程中,影响用户参与行为的要素主要包括动机、能力、提示、内容与环境。因此,可以通过分解用户行为,明确用户对影响要素的关注点,作为优化用户体验的基础。第二,论证参与行为类型与阅读体验维度的对应关系应当是:围观式行为一一般性体验、行动式行为一支撑性体验、话语式行为——高峰性体验,并纵向观察三者在参与程度上构成用户参与行为影响要素的层次。第三,从产品体验的视角横向梳理成三个阶段,分别是印象感知和采纳阶段、互动参与和发展阶段、持续参与和维持阶段。综上所述,整体地输出适用于各阶段的设计策略,依次为采纳阶段的基于宁静交互的平衡感知策略、发展阶段的基于用户行为的互动体验策略、维持阶段的基于激励积累的持续参与策略,系统地为数字阅读领域的用户体验提供新的观察视角与参考路径。阅读行为感知可以帮助我们评估阅读材料的可读性和易读性。哪个阅读行为感知费用
精细阅读感知,让理解更加深入透彻。江西信息阅读行为感知
信息抽取是指从多源异构的数据源中提取出实体、属性以及实体之间的关系,在此基础上形成本体化的知识表达,它是知识图谱构建技术的关键[1]。早期信息抽取主要是基于预定规则的抽取技术,工作量庞大且*适用于特定的专业领域,后来人们开始尝试使用统计机器学习的方法,通过标注部分数据得到训练集,在此基础上再使用均方根误差算法(rootmeansquarederror,RMSE)或多项式回归算法(polyno⁃mialregression,PR)等有监督学习算法识别命名实体。江西信息阅读行为感知