商机详情 -
循环利用
ADM产品生产数据备份恢复与异地容灾对生产数据包括数据库、文件、虚拟化平台、容器、云服务器等进行备份,对带库进行数据归档,支持长久增量备份、数据压缩存储、加密传输、重复数据删除等技术,采用挂载恢复方式,恢复时间为分钟级、恢复粒度为秒级。支持数据远程复制实现异地容灾,对备份数据进行双重保护。
ADM产品备份数据自动化恢复与有效性验证ADM可以对接备份系统如NetBackup、CommVault、NetWorker等,检索备份策略自动恢复备份数据和备份文件,完成验证输出结果。全自动化恢复验证,可以满足用户对当前备份数据的可恢复性验证、恢复后的完整性验证,覆盖备份数据和备份文件的恢复,支持虚拟挂载恢复和物理恢复双重方式。 上讯ADM产品参加2023年度数据安全优*案例评选活动取得“标准化安全产品类优*案例”证书。循环利用
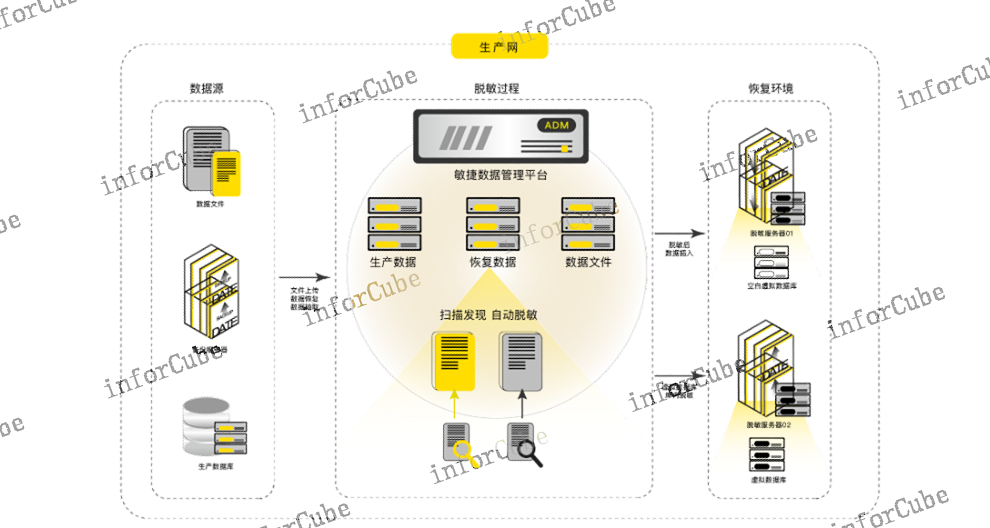
敏捷数据管理平台ADM的关键技术如下:l***数据获取方式数据获取的目的是将不同的数据源实时或者按需同步到平台内,根据不同类型的数据源,数据获取方式分为三种,保证覆盖全部数据源获取方式:①支持实时同步应用数据库;②支持按需同步关系型数据库;③支持与备份系统对接恢复数据。l核心专利技术—数据库虚拟化技术ADM内置一套数据库虚拟化管理程序,虚拟数据库是通过一份基础数据源创建的数据副本,一份基础数据源可以生成多个虚拟数据库,虚拟数据库可读可写,虚拟数据库状态可实时保存。虚拟数据库创建时间为分钟级,且不占用额外的存储空间。敏感类型定制化ADM支持多线程文件备份,支持海量小文件场景下的聚合策略进行文件备份。
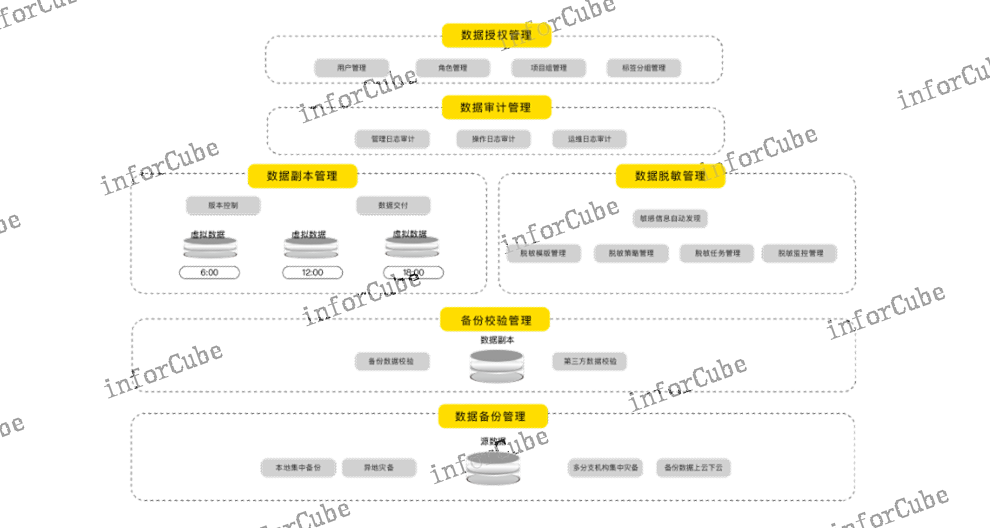
数据副本管理是ADM功能模块之一,可单独作为企业级副本数据管理(CDM)产品。为应对当前复杂的IT环境,ADM提出集云、物理、虚拟为一体的,面向结构化数据库、非结构化数据、虚拟化和云平台的***数据副本分发与交付管理解决方案。主要通过数据副本管理的核心专利技术——数据库虚拟化技术对源数据进行CDM原格式获取生成黄金副本、存储黄金副本作为基准数据、虚拟化为多个副本挂载恢复,**终达到快速交付副本数据、灵活管理副本数据版本、集中管理副本数据存储与流转的目标,是主要面向企业数据运维、软件开发测试部门解决自动化闭环取数供数、测试数据快速交付等典型应用场景的问题。
ADM平台具备根据管理人员、测试需求等内容的不同进行分组划分的功能,将处理过的数据进行分组管理,从下游测试数据管理的源头管控数据资源的类别,做到从源头划分类别,使下游测试数据管理形成上游数据源-中游数据中转-下游数据目标的闭环式数据使用流程,规范化的数据流程使数据管理者成为数据的负责人,自动化的资源管理也更有效地为金融行业用户提供安全的数据管理方案。同时,ADM提供对数据流转的树状拓扑结构图,可详细了解数据的来源、所属存储池、挂载的测试服务器,以及数据快照的层级关系,方便对系统全局的数据使用结构进行预览,通过可视化的结构拓扑图,帮助用户了解下游测试网中测试数据的归属关系,完善数据流转路径,优化数据资源的合理分配,可视化功能的动态展示将助力企业向着智能化数据安全治理的方向转型。ADM数据备份管理可针对数据库、文件、虚拟机进行备份恢复。
用户提出数据管理产品的上线既要满足云技术的部署带来数据迁移和历史备份数据接管的要求,又要对用户系统更新迭代导致副本数据使用管理需求增加、测试场景需求增加的问题予以解决,因此用户对CDM的部署方式提出了要求:即适应混合多云环境,支持BaaS和订阅的模式部署。敏捷数据管理平台(ADM)产品具备灵活的部署模式,既支持单机部署,也支持高可用部署、多云混合部署,且每个功能均支持在线扩展,具备扩展的便捷性。在混合多云环境中,只需要将ADM在每朵云中进行部署,即可实现备份数据、副本数据的多云间统一管理,并支持在每朵云中创建虚拟数据,实现数据的分钟级快速交付;在云环境中的测试环境,可以利用云主机的快照功能及ADM的虚拟数据功能,达到整个测试环境的版本管理(包括系统、数据),达到数据使用及管理的便利性.ADM在处理数据上中下游流转的过程是集中统一的,通过全闭环式的传输保证了数据的安全。备份数据的完整性
ADM的静态数据脱*功能是满足数据安全法规的监管要求的脱*平台。循环利用
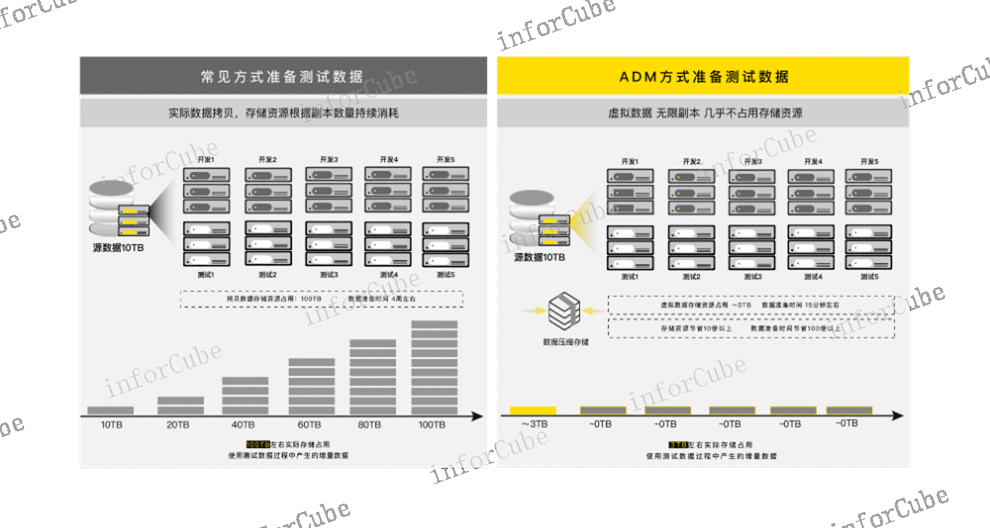
功能节点统一管理,支持弹性扩展ADM采用多节点高可用部署架构,保障数据服务高可用,并消除单节点故障导致的业务不可用问题,确保数据服务连续性。采用Scale-out架构,根据业务发展规模,按需扩展集群节点,无需停止服务,灵活满足业务需求。同时,ADM支持存储池容量的弹性扩充,满足不断增长的数据存储需求。(2)数据存储成本倍数级节约,提升数据存储环节的效能首先,数据备份面临存储成本高的问题,ADM采用内置高效的压缩存储池存放数据,压缩比约为3:1,存储即压缩,***降低了备份数据的存储成本;其次,通过ADM的数据库虚拟化技术,一份基础数据即可快速拉起多份虚拟数据库,由于虚拟数据库90%的数据均与原始数据相同,因此拉起时几乎不占用额外的物理存储空间,*对新增的写操作计入容量占用,因此,随着数据分发使用的场景和频率增加,虚拟库的数量越来越多,而存储成本将会呈倍数级节约,例如针对同一份数据创建N个虚拟库,传统方法需要N倍的存储空间占用,而通过ADM只需要占用近乎0TB的存储空间,**节约了数据存储环节的资源和成本。循环利用