商机详情 -
北京高质量数据集
北京明曦数智科技高质量数据集集成联邦学习与多方安全计算技术,构建“数据可用不可见”的合规流通范式。在数据标注阶段采用差分隐私保护机制,通过拉普拉斯噪声注入确保个体信息不可逆向推导。针对跨境数据流动需求,设计细粒度权限控制系统。经中国信通院隐私计算测评,其数据泄露风险低于0.01%,满足GDPR与《数据安全法》双重要求。已在医疗科研领域实现多家医院数据协同建模,患者隐私零泄露前提下,疾病预测模型AUC提升至0.912。明曦数智构建了多语种平行语料库,严格对齐句对,服务于机器翻译引擎训练。北京高质量数据集
数据集的版本管理是明曦数智数据工程的一部分。每次数据更新、标注规则调整或样本增删,都会生成新的版本并记录变更日志。这包括数据量变动、标注员信息及质检结果差异。通过版本回溯,能够定位模型训练效果波动的原因,支持迭代优化数据集内容。
在语音数据集建设中,明曦数智关注录音环境与说话人分布的多样性。采集时会覆盖不同信道、背景噪声等级及方言口音,并对音频进行静音切除与音量归一化处理。转写文本经过多轮校对,确保与语音段严格同步,标点使用符合规范,以适应语音识别模型的训练要求。 北京高质量数据集通过采集不同时段的交通流数据,明曦数智构建了反映真实路况的动态数据集。
明曦数智在构建中文诗歌数据集时,并没有简单地按朝代或作者分类,而是深入到了格律和韵脚的层面。对于古诗词,团队标注了平仄、对仗和押韵情况;对于现代诗,则分析了意象的使用频率和情感基调。这项工作极其枯燥,需要标注员具备一定的文学素养。但正是这些深层特征的标注,使得该数据集不只能用来做简单的文字生成,还能用于文学风格的迁移研究。比如,训练出的模型能分辨出李白和杜甫风格的差异,而不只*是背下他们的诗。这种深度的数据加工,是把“文化”变成“数字资产”的必经之路。
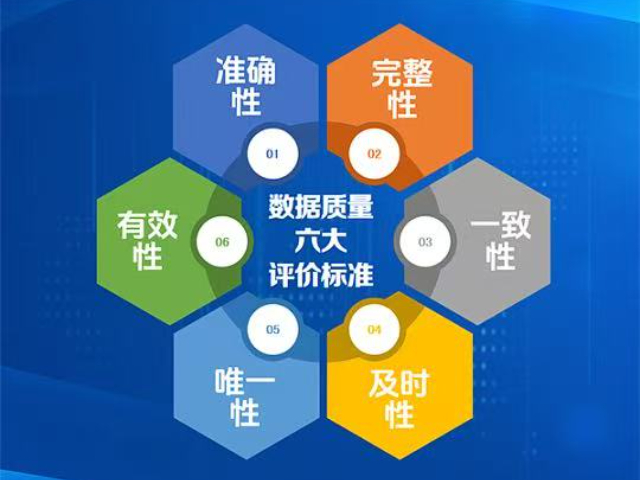
明曦数智对数据集中的“脏数据”有着独特的辩证看法。在工程实践中,并非所有的“脏数据”都要被清洗掉。例如在构建地址数据集时,用户经常会输入错别字或简称(如把“朝阳区”写成“朝阳区”)。如果全部清洗成标准写法,模型就学不会如何处理用户的输入错误。因此,团队会保留一定比例的“噪声数据”,并将其与标准数据建立映射关系。这种策略模拟了真实世界用户输入的不规范性,让训练出的地址解析模型具备了更强的容错能力。这种取舍是基于对业务场景的深刻理解,而非单纯追求数据的理论完美度,体现了工程落地的智慧。通过持续的数据清洗与回流,明曦数智确保了数据集在业务演进中的长期有效性。

针对智慧城市的能耗数据集,明曦数智关注的是数据采集的频率与粒度。如果按小时采集全市的水电表数据,虽然数据量适中,但很难分析出瞬时峰值。团队会根据区域重要性,动态调整采集频率,商业区按分钟级采集,居民区按小时采集。同时,在数据入库前,会进行严格的单位换算,确保所有数据的计量单位统一(如统一为千瓦时)。这种看似琐碎的单位核对工作,避免了后期数据分析时出现“千倍误差”的低级错误,确保了城市管理者在制定节能政策时有据可依,数据是靠谱的。通过关键点标注技术,明曦数智实现了对人体姿态与动作的高精度行为分析数据集。北京高质量数据集
通过融合多传感器时序数据,明曦数智构建了高精度的设备故障预警数据集。北京高质量数据集
明曦数智在构建地图POI(兴趣点)数据集时,建立了一套动态的生命周期管理机制。商铺的开业与倒闭是常态,如果数据集不及时更新,导航软件就会把用户引向已经关门的大楼。团队通过结合街景图像变化、用户反馈投诉以及工商注册信息,建立了POI的活跃度评分模型。对于那些长期无动态、疑似倒闭的店铺,系统会自动将其状态置为“待核实”,并安排外业人员进行实地核查。这种“活”的数据维护机制,虽然运营成本较高,但确保了地图数据的鲜度,直接关系到亿万用户的出行体验。北京高质量数据集
北京明曦数智科技有限公司是一家有着雄厚实力背景、信誉可靠、励精图治、展望未来、有梦想有目标,有组织有体系的公司,坚持于带领员工在未来的道路上大放光明,携手共画蓝图,在北京市等地区的商务服务行业中积累了大批忠诚的客户粉丝源,也收获了良好的用户口碑,为公司的发展奠定的良好的行业基础,也希望未来公司能成为*****,努力为行业领域的发展奉献出自己的一份力量,我们相信精益求精的工作态度和不断的完善创新理念以及自强不息,斗志昂扬的的企业精神将**北京明曦数智科技供应和您一起携手步入辉煌,共创佳绩,一直以来,公司贯彻执行科学管理、创新发展、诚实守信的方针,员工精诚努力,协同奋取,以品质、服务来赢得市场,我们一直在路上!