商机详情 -
怎样上讯数据网关信息中心
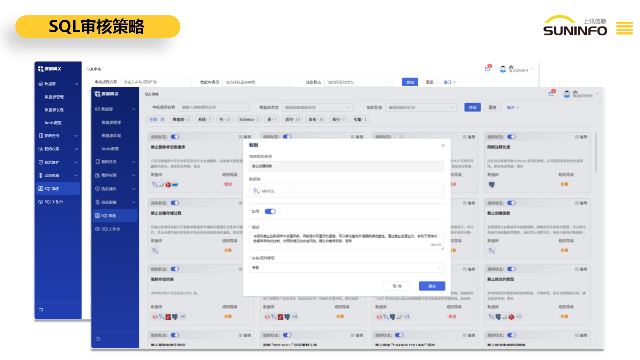
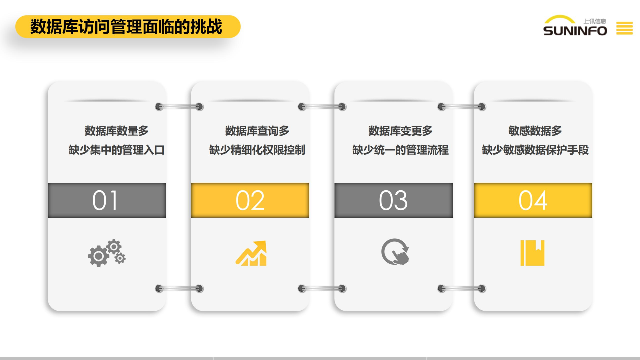
上讯数据网关DG数据源管理主要具备以下能力:连通性测试:为确保数据源的可用性,数据源支持对数据源连通性的测试功能,及时发现数据库连接问题,提高数据管理的稳定性。实时数据更新:数据网关DG能够实时更新数据源中的数据,以确保系统获取到***的业务信息,保障数据的准确性和实效性。批量导入数据源:提供模板化、批量导入数据源的功能,以简化大规模数据源的配置流程,提高操作效率。快速发现数据源:数据源管理需具备快速发现数据源的能力,可以根据局域网IP段和指定数据源端口迅速发现数据源,提高系统自动发现的效率。域名通信管理:针对域名通信的数据源,支持在hosts配置中添加域名和IP映射关系,代替后台操作,以提供更为便捷的数据源管理方式,符合日常操作习惯。访问控制管理:支持对数据库进行访问控制管理,限定只有指定的数据库客户端、数据库账号、访问IP及数据库账号、访问IP,才能访问访问数据库,有效确保数据库的访问安全。上讯数据网关DG关联脱敏策略,对查询出的数据展示动态脱敏效果,防止了企业内部敏感数据的外泄风险.怎样上讯数据网关信息中心

数据雷达提供了多种分类分级算法,包括AI大模型算法、正则算法、字典算法和应用算法,旨在满足用户不同的分类需求,提高数据分类的准确性和效率。正则算法:(1)自定义正则:用户可以通过编写正则算法来对数据进行分类分级,根据自身业务需求,灵活定义匹配规则,实现数据的准确分类。(2)多字段打标支持:支持多字段方式,用户可以针对多个字段进行正则匹配,并根据匹配结果对数据的级别和类别进行打标,实现更加精细化的数据分类。(3)多算法配置:用户可同时配置多个正则算法进行逻辑操作,包括与、或、非等功能。通过组合不同的正则算法,可以实现更复杂的数据分类逻辑,提升分类准确性和灵活性。怎样上讯数据网关信息中心上讯数据网关DG操作日志及审计功能可提供完整的、可追溯的操作记录,以加强对数据访问和平台活动的监控.
数据网关DG提供虚拟的数据访问功能,通过字段级别的权限划分和细颗粒度的权限管控,确保对访问数据源的用户进行有效的权限管理,保障数据的安全和隐私。查询大表控制:数据网关DG能够有效地控制对大表的查询结果集访问条数,优化查询性能,确保系统稳定运行。提供内置的SQL工作台,通过浏览器Web页面对数据库进行操作。用户可以通过友好的图形化界面进行数据库查询、修改、管理等操作,无需额外的客户端软件,增强了用户操作的灵活性和便利性。客户端和工具支持:通过使用数据网关的JDBC驱动,用户可以在数据库客户端(如DBeaver、Datagrip)和BI分析工具(如SmartBI、帆软Report)中进行数据库操作,拓展了数据访问和分析的应用场景。
数据网管在监控网络流量方面扮演着重要的角色。通过对网络流量的实时监测和分析,他们能够了解网络的使用情况和趋势。流量监测可以帮助数据网管发现异常的流量模式,如突然的流量峰值或持续的高流量消耗。这可能是由于网络攻击、病毒传播或某个应用程序的异常行为导致的。通过深入分析流量数据,数据网管可以确定哪些应用程序或用户占用了大量的网络资源,并采取相应的措施进行优化或限制。例如,如果发现某个部门在工作时间内大量下载娱乐内容,导致网络拥堵,数据网管可以与该部门沟通,制定合理的网络使用政策,以确保网络资源的公平分配和有效利用。此外,流量监测还为网络规划和升级提供了重要的依据。根据流量的增长趋势,数据网管可以提前规划网络扩容,以满足未来业务发展的需求。
上讯数据网关产品数据库兼容性更好、稳定性和性能更高。
支持虚拟化代理方式查询,为数据访问者提供高效的跨源数据联邦查询和计算,**降低了数据搬运的存在,降低存储资源的消耗,提高数据分析的效率。虚拟账号访问:无需使用数据库的实体账号,通过数据网关的虚拟账号即可访问后端数据库。这种设计提升了安全性和管理便捷性,虚拟账号的使用降低了实体账号泄露的风险,同时简化了用户管理和权限分配的工作。数据库目录展示:以树状形式展示用户有权限访问的数据库对象的元数据信息,包括表、视图、存储过程等,帮助用户***了解数据库结构。本地文件源管控:支持操作员直接添加本地数据源,不受权限管控,操作员可以在没有严格权限限制的情况下,自由地管理和操作本地文件数据源,简化了数据源的添加和使用流程,提高了操作效率和灵活性。上讯数据网关实现运维过程中的事前预防、事中管控和事后审计。怎样上讯数据网关信息中心
建立细颗粒度的权限控制机制,根据用户角色和需求对数据访问权限进行精确控制是必不可少的。怎样上讯数据网关信息中心
数据雷达DR基于AI大模型进行分类分级:在实现数据分类分级的过程中,语义级别的数据分类分级引擎采用了基于AI大模型的先进技术。这一引擎能够同时对数据类型进行词法、语法和语义级别的特征提取和分析,从而建立起语义级别的高维度特征向量。通过这种方式,引擎能够更加准确地理解和区分不同类型的数据,提高了数据分类分级的精确度和可信度。基于数据字段内容的模型训练,保证了数据分类分级模型的可复制性:语义级别的数据分类分级引擎注重保证数据分类分级模型的可复制性,采用AI大模型进行训练时,引擎不依赖于数据字段的名称和注释,即使在没有明确的字段描述情况下也能够达到很高的准确度。这意味着训练后的数据分类分级模型在不同的数据环境下都能够稳定可靠地运行,具有很高的适用性和通用性,为数据管理和安全保障提供可靠的支持和保障。 怎样上讯数据网关信息中心