商机详情 -
山西高质量数据集技术指导
明曦数智数据集作为通用人工智能基座,支持千亿参数级大模型预训练。采用掩码语言建模与对比学习相结合的自监督框架,从无标注数据中学习深层语义表示。针对中文语境优化分词器与位置编码,提升古文、方言、专业术语的理解能力。数据集包含5TB高质量文本与1亿张图像-文本对,覆盖科技、文化、经济等多元领域。在CLUE中文理解榜单中,基于该数据集训练的模型取得88.7分,超越人类平均水平。开放API接口支持企业微调,降低行业大模型研发门槛。
明曦数智为工业质检数据添加了物理尺寸标签,辅助算法进行准确的公差判定。山西高质量数据集技术指导

在构建智能家居的语音指令数据集时,明曦数智充分考虑了中国各地的方言口音差异。标准的普通话数据集训练出的音箱,在家庭环境中往往听不懂老人说的家乡话。为此,团队招募了来自不同省份的方言发音人,采集带有浓重口音的普通话指令,如“把灯关咯”、“开一哈空调”。为了提高数据的多样性,团队还在录音过程中模拟了真实家居环境,加入了电视背景音和厨房炒菜声。这种充满生活气息的数据集,虽然听起来不如播音员那样悦耳,但训练出的产品却更接地气,更能听懂老百姓的话。山西高质量数据集技术指导明曦数智对网络公开数据执行版权筛查,确保训练数据来源合法,规避法律风险。
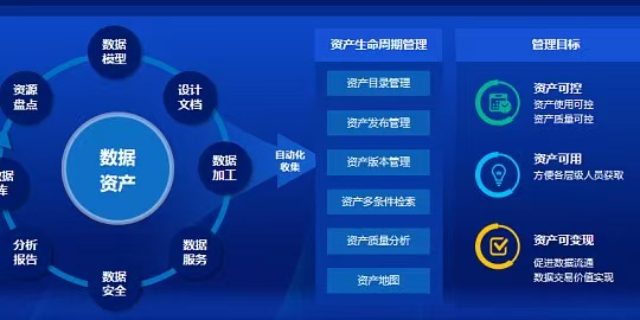
在构建法律文书数据集时,明曦数智采用了严格的结构化并行策略。法律文书中包含大量的个人隐私和商业机密,直接删除这些信息会破坏文书的连贯性。因此,团队设计了一套实体替换规则,将当事人的姓名替换为“[原告]”、“[被告]”,将公司名替换为“[甲公司]”、“[乙公司]”。同时,为了保证法律逻辑的完整,团队会保留文书中的法条引用编号和判决结果。这种处理方式既满足了《个人信息保护法》的要求,又让模型能够专注于学习法律推理的逻辑链条,而不是记住具体的某个人名。这种兼顾合规与效用的做法,是数据工程中难得的平衡艺术。
明曦数智新能源数据集整合卫星遥感、气象站、设备传感器等多源数据,覆盖光伏、风电、储能等全场景。创新性地引入大气物理模型修正数值天气预报偏差,构建地形-气候耦合特征矩阵。针对分布式光伏,开发基于计算机视觉的阴影遮挡分析模块,精细量化树荫、建筑物对发电效率的影响。数据集包含过去10年每小时粒度的功率曲线,支持超短期(15分钟)、短期(72小时)及中长期(月度)多尺度预测。在某省级电网应用中,将弃光率从12.3%降至6.8%,年增清洁能源消纳1.2亿千瓦时。针对古籍数字化,明曦数智处理了异体字与版式错位,还原了文献的原始结构。

针对多模态数据集的建设,明曦数智注重图文音视之间的对齐精度。在处理视频数据时,会同步校准时间戳与对应帧的图像特征及语音转写文本。通过自动化脚本初筛加人工细查的方式,解决模态错位问题,确保每条多模态样本在语义和时序上的对应关系准确可靠。
在数据集的合规性管理上,明曦数智执行数据权限管控流程。对于涉及个人隐私或敏感信息的字段,采用泛化、遮蔽或去标识化技术处理,并记录数据流转日志。同时,数据集交付时会附带元数据说明,明确数据来源、授权范围及使用限制,满足合规审计要求。 明曦数智在语音数据采集中,覆盖多种方言与噪声环境,增强模型的抗干扰能力。山西高质量数据集技术指导
明曦数智清理了社交媒体中的机器人水军数据,提纯真实有效的用户行为特征。山西高质量数据集技术指导
明曦数智在标注电商商品主图时,严格执行了“主体突出”的清洗规则。很多商家为了美观,会在主图上添加大量的促销水印、文字标签或搭配无关的装饰品。这些元素对于计算机视觉模型来说都是干扰项,容易导致模型关注不到商品本体。团队利用目标检测算法,自动识别出图片中面积占比较大的商品主体,并将那些主体占比过小、背景过于杂乱的图片判定为低质数据予以剔除。这种看似简单粗暴的筛选,实则是在帮模型“划重点”,确保训练出的识图模型能又快又准地抓住关键信息。山西高质量数据集技术指导
北京明曦数智科技有限公司在同行业领域中,一直处在一个不断锐意进取,不断制造创新的市场高度,多年以来致力于发展富有创新价值理念的产品标准,在北京市等地区的商务服务中始终保持良好的商业口碑,成绩让我们喜悦,但不会让我们止步,残酷的市场磨炼了我们坚强不屈的意志,和谐温馨的工作环境,富有营养的公司土壤滋养着我们不断开拓创新,勇于进取的无限潜力,北京明曦数智科技供应携手大家一起走向共同辉煌的未来,回首过去,我们不会因为取得了一点点成绩而沾沾自喜,相反的是面对竞争越来越激烈的市场氛围,我们更要明确自己的不足,做好迎接新挑战的准备,要不畏困难,激流勇进,以一个更崭新的精神面貌迎接大家,共同走向辉煌回来!