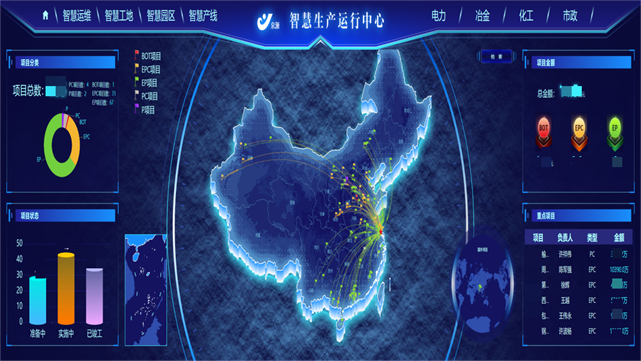
商机详情 -
海南智慧运维平台
业务连续性规划(BCP)严重依赖于对系统依赖关系和风险点的准确认知。智慧运维平台中动态生成的应用拓扑图、梳理出的关键业务链路、以及历史故障影响范围分析,为制定准确的BCP提供了较真实的数据基础。平台可以模拟不同灾难场景(如单个AZ故障、数据库宕机)对业务的影响,并验证容灾切换方案的有效性。这使得BCP从一份静态的文档,变成了一个基于实时系统状态、可数据化验证的动态管理过程。没有一个平台能解决所有问题,因此智慧运维平台的生态与集成能力至关重要。良好的平台应提供丰富的API、SDK和插件机制,能够轻松与现有的ITSM、CMDB、自动化工具、通信平台(如Slack、钉钉)以及云服务商的原生监控服务集成。通过构建一个开放的生态系统,智慧运维平台可以成为运维工具链的“指挥中心”,聚合各方数据与能力,而不必替代所有工具,从而以更灵活、更低成本的方式创造价值。形成可视化报表和动态图表。海南智慧运维平台
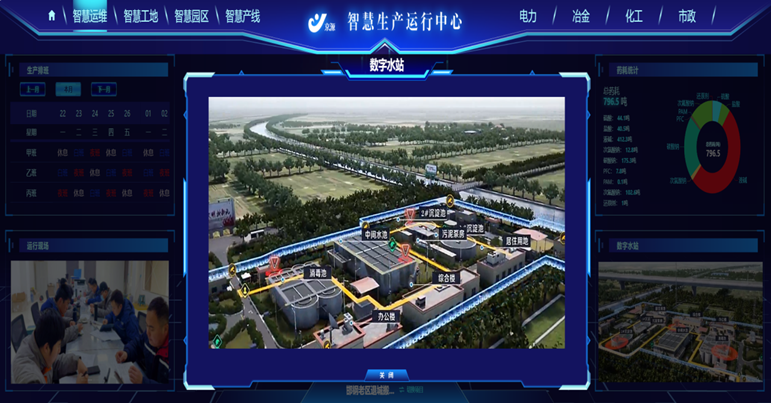
作为一个复杂系统,智慧运维平台自身也必须具备高度的可观测性。平台需要监控其数据采集管道的健康度、数据处理的延迟、AI模型的准确率、API的调用性能等。当平台自身出现数据断流、分析延迟或错误时,应能自我感知、自我告警。确保平台自身的稳定、可靠是其为业务系统提供可信服务的前提,这也是“Eating your own dog food”理念在运维领域的体现。在DevOps文化中,智慧运维平台扮演着“反馈中枢”的角色。它将生产环境的真实运行数据(如性能指标、错误日志、用户反馈)持续、透明地反馈给开发团队。这些数据被集成在CI/CD流水线中,成为定义“Done”的标准之一(不仅功能完成,还需满足性能基线)。这种基于数据的快速反馈闭环,驱动开发人员编写更健壮、更易于监控的代码,促进了开发与运维的深度协作,是构建高质量、高韧性软件系统的关键。北京智慧运维平台电话资源匹配模拟优化项目开工时间规划。

可观测性(Observability)是智慧运维的基石,它超越了传统的监控概念,强调从系统外部输出(如日志、指标、追踪)中,能够理解和推断系统内部状态的能力。一个具备高度可观测性的平台,能够让我们不仅知道系统“出了什么问题”,更能理解“为什么会出问题”。它通过整合日志(Logging)记录离散事件、指标(Metrics)反映聚合状态、链路追踪(Tracing)描绘请求全景,构建了理解复杂分布式系统的三维数据模型。没有完善的可观测性数据基础,后续的AI分析与自动化就如同无源之水,智慧运维也就无从谈起。
为了应对业务的快速变化,智慧运维平台需要具备足够的灵活性,允许运维人员快速定制监控视图、分析场景和自动化流程,而无需等待开发团队的支持。低代码/无代码(LCNC)能力在此背景下显得至关重要。通过图形化拖拽、表单配置和规则引擎,业务运维人员可以自主搭建监控大屏、定义复杂的告警规则、编排自动化处理流程。这极大地降低了平台的使用门槛,加速了运维响应的速度,并使得平台能够更好地适配不同业务线的独特需求,真正成为一个由运维人员主导、随需而变的敏捷工具。
智慧运维平台借助人工智能算法重构了告警体系,彻底解决了传统运维中 “告警风暴” 的痛点。平台通过对历史告警数据进行训练,建立了多维度告警关联模型,能够自动识别重复告警、次要告警,并根据业务优先级进行分级推送;同时引入异常检测算法,可基于系统基线自动识别偏离正常运行状态的指标波动,实现 “未发先觉” 的预警能力。例如当服务器 CPU 使用率异常攀升时,系统会结合内存占用、业务请求量等数据综合判断,但向运维人员推送高价值告警,有效降低告警噪音,让运维精力聚焦于关键问题处理。动态时间轴追溯历史项目数据及未来规划。市政智慧运维平台厂家
快速响应设备故障启动维修流程。海南智慧运维平台
日志中蕴含着系统行为的较详细记录,但其非结构化的特性使得分析异常困难。智慧运维平台的日志智能分析功能,通过日志解析模板和自然语言处理(NLP)技术,自动将海量杂乱日志结构化,提取出关键事件、错误码和用户ID。平台能够对日志模式进行聚类分析,快速发现罕见的错误模式;能够基于日志序列预测系统故障;还能够通过日志关键词的突然增多,感知到潜在的安全威胁。这使得日志从“事后查证”的档案,变成了“实时洞察”的情报源。海南智慧运维平台