商机详情 -
青海智慧运维平台公司
自动化是智慧运维价值闭环的“然后一公里”。当平台通过分析诊断出问题根因并形成解决方案后,需要有能力自动执行修复动作。这可以通过预置的自动化剧本(Playbook)或与RPA、Ansible、Kubernetes Operator等自动化工具集成来实现。常见的自愈场景包括:自动重启异常进程、自动扩容应对流量洪峰、自动隔离故障节点、自动修复磁盘空间等。实现自愈不仅极大降低了人工干预成本和人为失误风险,更重要的是,它使得系统具备了在无人值守情况下自我恢复的能力,为实现真正的“无人运维”愿景奠定了坚实基础。地图支持按特定需求检索项目。青海智慧运维平台公司
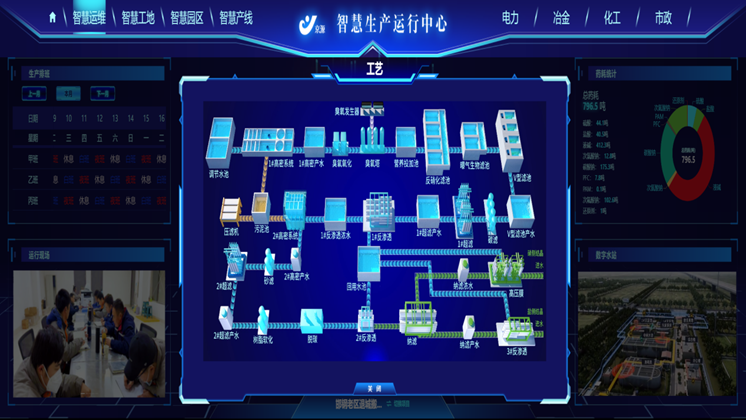
为了应对业务的快速变化,智慧运维平台需要具备足够的灵活性,允许运维人员快速定制监控视图、分析场景和自动化流程,而无需等待开发团队的支持。低代码/无代码(LCNC)能力在此背景下显得至关重要。通过图形化拖拽、表单配置和规则引擎,业务运维人员可以自主搭建监控大屏、定义复杂的告警规则、编排自动化处理流程。这极大地降低了平台的使用门槛,加速了运维响应的速度,并使得平台能够更好地适配不同业务线的独特需求,真正成为一个由运维人员主导、随需而变的敏捷工具。

针对中小微企业 IT 资源有限、运维人员不足的痛点,智慧运维平台推出了轻量化版本解决方案。该版本简化了部署流程,支持快速上线使用,同时保留主要的监控、告警、基础自动化功能;提供按需付费的云服务模式,降低企业初始投入成本;内置行业通用运维模板,无需专业运维人员即可完成系统配置;通过远程运维支持服务,为中小微企业提供技术保障,帮助其以较低成本实现运维数字化升级。智慧运维平台通过大数据分析技术深度挖掘运维数据的价值,将数据转化为业务增长动力。平台对监控数据、日志数据、运维操作数据等进行多维度分析,生成系统运行报告、故障分析报告、能效优化报告等,为 IT 架构优化、资源扩容、成本控制提供数据支撑;通过分析运维数据与业务数据的关联关系,识别系统瓶颈对业务的影响,例如通过分析用户访问延迟与交易成功率的相关性,优化系统性能以提升业务收入;同时支持数据导出与共享,为企业经营决策提供参考。
作为一个复杂系统,智慧运维平台自身也必须具备高度的可观测性。平台需要监控其数据采集管道的健康度、数据处理的延迟、AI模型的准确率、API的调用性能等。当平台自身出现数据断流、分析延迟或错误时,应能自我感知、自我告警。确保平台自身的稳定、可靠是其为业务系统提供可信服务的前提,这也是“Eating your own dog food”理念在运维领域的体现。在DevOps文化中,智慧运维平台扮演着“反馈中枢”的角色。它将生产环境的真实运行数据(如性能指标、错误日志、用户反馈)持续、透明地反馈给开发团队。这些数据被集成在CI/CD流水线中,成为定义“Done”的标准之一(不仅功能完成,还需满足性能基线)。这种基于数据的快速反馈闭环,驱动开发人员编写更健壮、更易于监控的代码,促进了开发与运维的深度协作,是构建高质量、高韧性软件系统的关键。助力管理者掌握系统运行状态。
智慧运维平台的深入应用,必然催生运维组织架构与文化的协同演进。传统的运维团队中,网络、系统、数据库、应用各司其职的“竖井”式结构,已无法适应云原生时代全栈、敏捷的需求。平台促使企业组建融合了开发、运维和安全技能的SRE团队或平台工程团队。这些团队基于统一的智慧运维平台进行协作,共享同一套数据和工具,共同对服务的可靠性、可用性和安全性负责。同时,平台将工程师从重复性的、低价值的告警确认和手工操作中解放出来,让他们能够将更多精力投入到架构优化、性能调优、流程改进和创新性项目中。这背后是一种文化变迁:从害怕变更、追求稳定,转向拥抱风险、通过可观测性和自动化来安全地加速创新。较终,智慧运维平台不仅只是一套技术解决方案,它更是一种赋能手段,塑造着一个更高效、更协同、更具创新力的现代IT组织,为企业的数字化转型提供较坚实的底层支撑。项目状态看板动态呈现全流程转化情况。黑龙江新能源智慧运维平台
可视化报表助力管理人员科学决策。青海智慧运维平台公司
企业在智慧运维平台建设上,面临自建(Build)与外购(Buy)的抉择。自建平台(基于开源组件如Elastic Stack、Prometheus、SkyWalking进行集成开发)具有高度的灵活性和可控性,能够深度定制以适应独特需求,但对团队技术实力、时间和持续投入要求极高。外购商业产品则能快速上线,享受厂商的持续研发和专业服务,但可能在成本、数据权利和与现有流程的集成度上存在挑战。企业需综合评估自身的技术能力、业务需求复杂度、预算和时间窗口,做出比较符合长期利益的战略选择。青海智慧运维平台公司